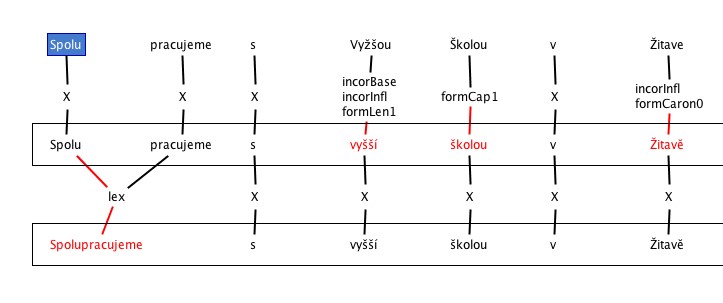
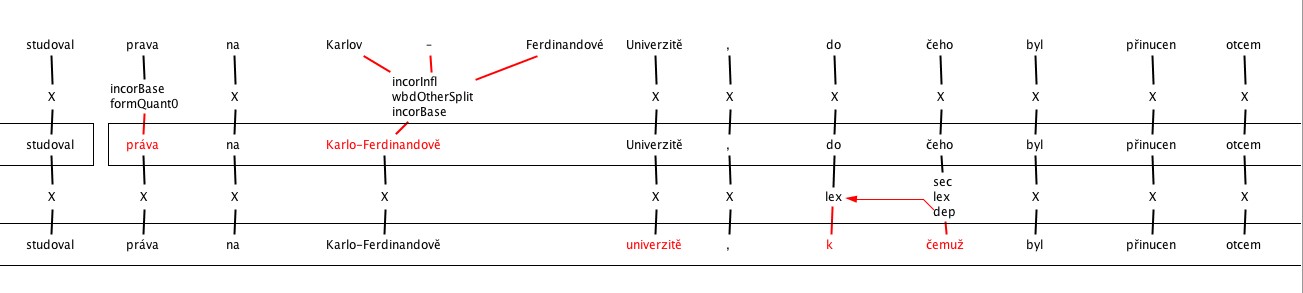
1. Predicting the most frequently recurring errors (L1 – POLISH, L2 – CZECH)
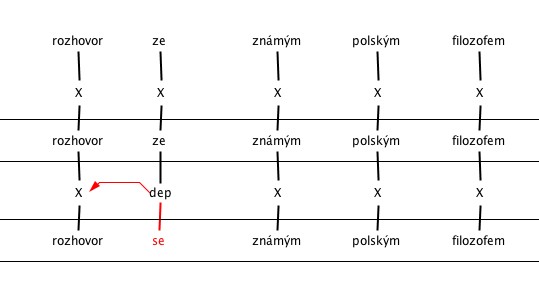
2. Searching for expected errors in the corpus. Errors considered to be the most common appeared in the annotation only occasionally.
3. Searching for errors in the feat program. The most frequently annotated errors were various types of deficiencies in the structure of the sentence (wrong word order).
- Word order – Auxiliaries
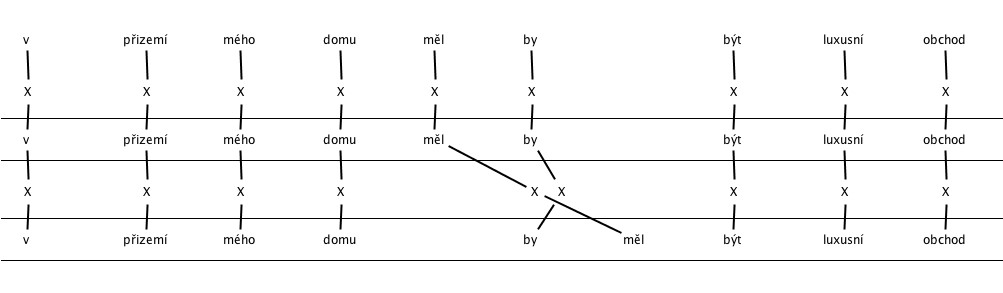
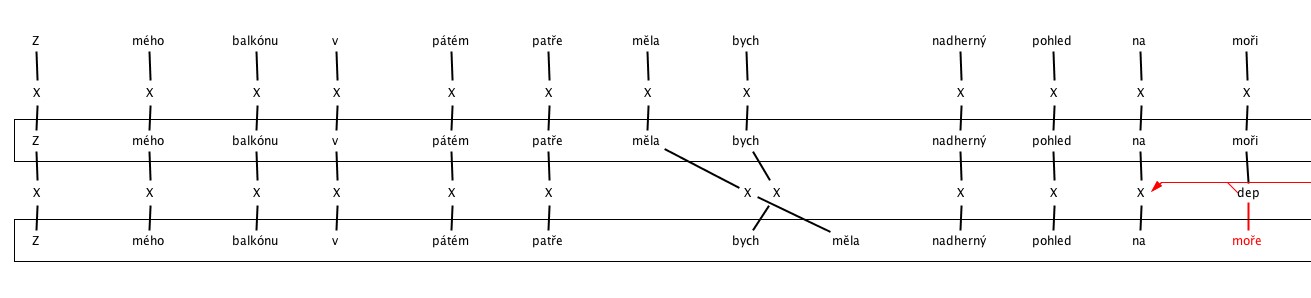
- Word order – Clitics
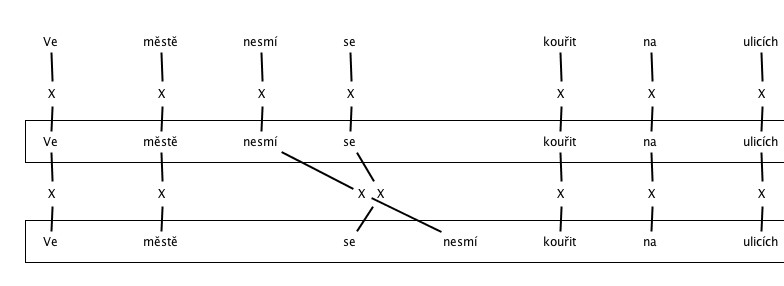
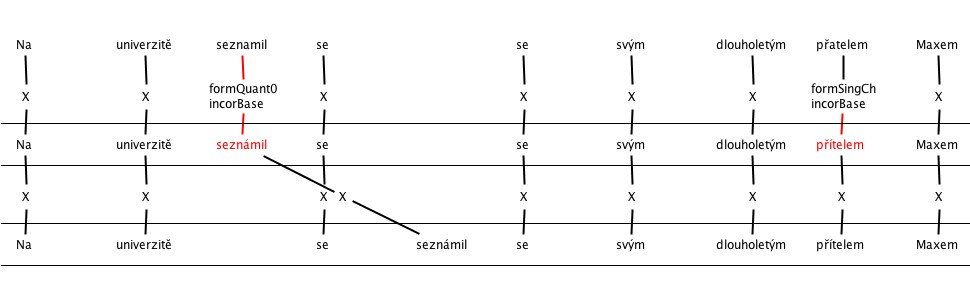
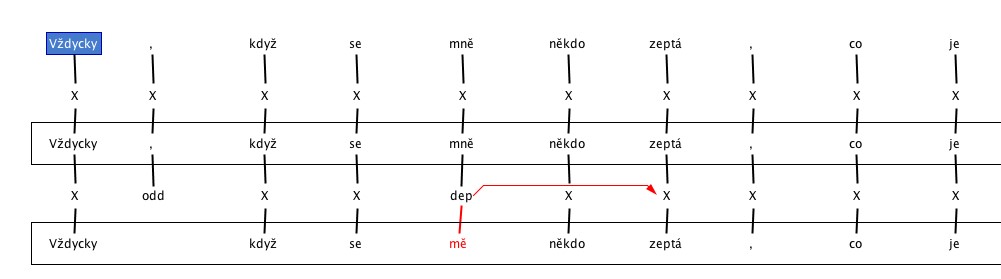
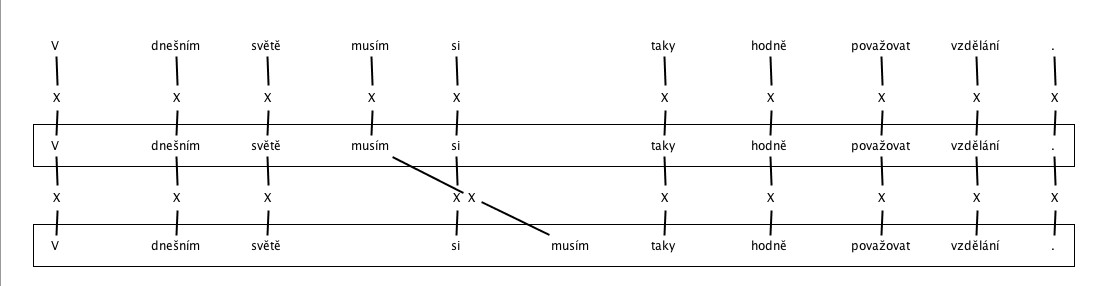
c. Word order – other
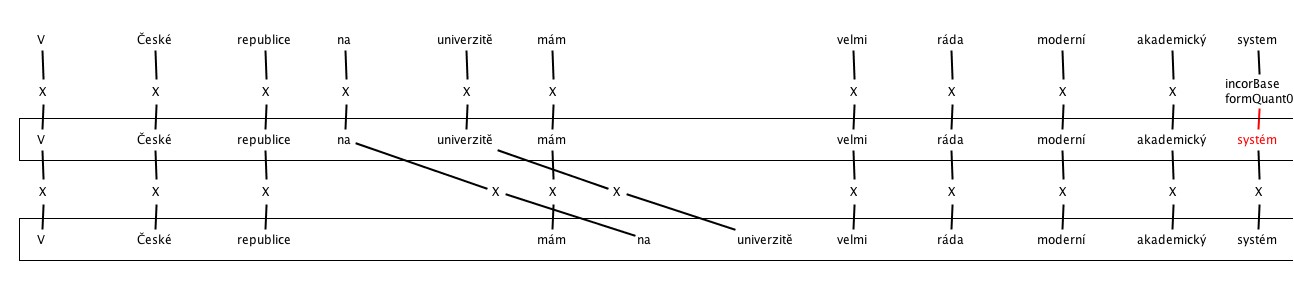
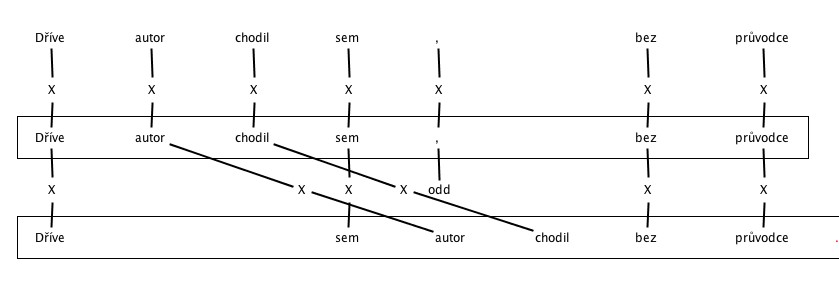
4. Errors in Vowel length
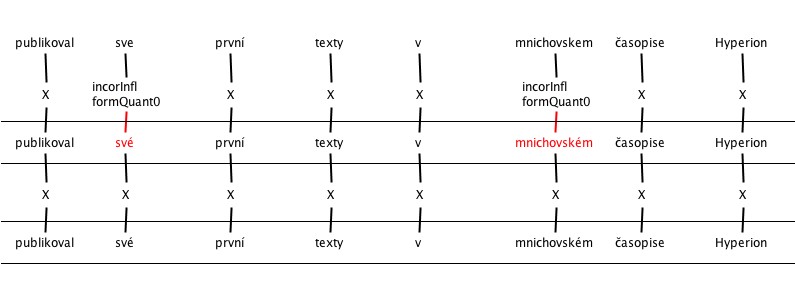
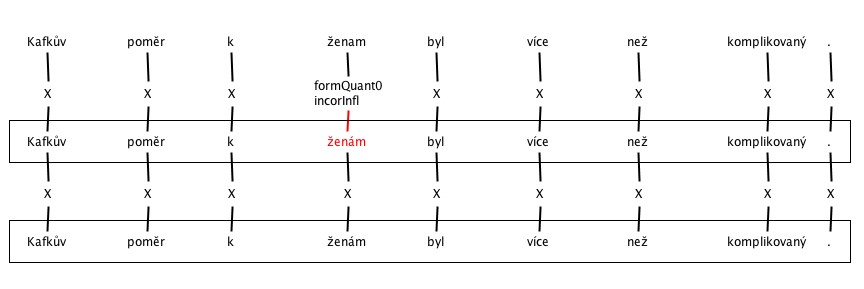
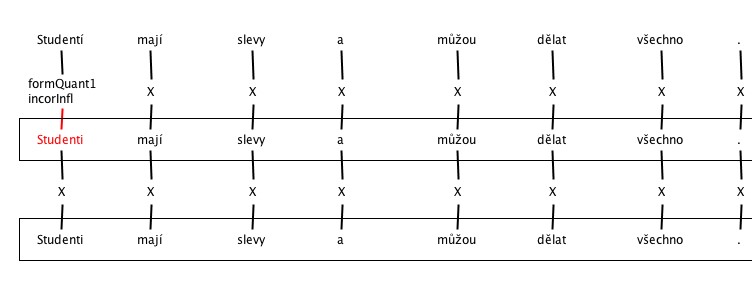
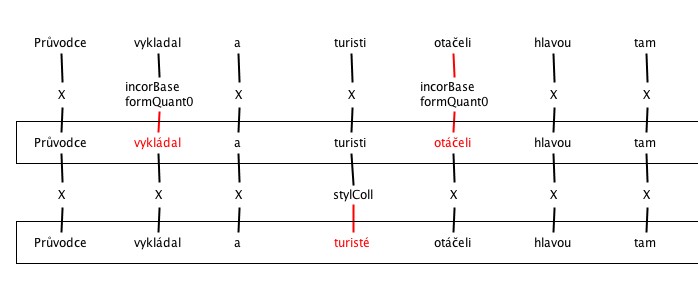
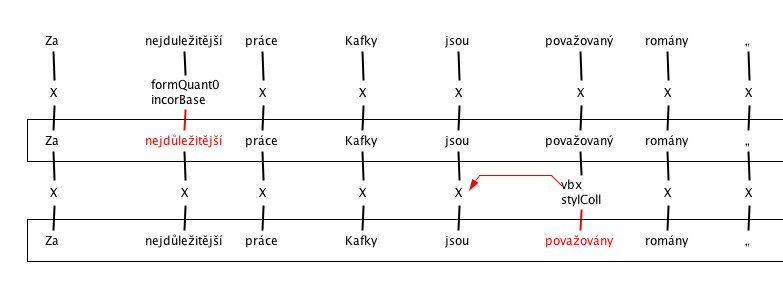
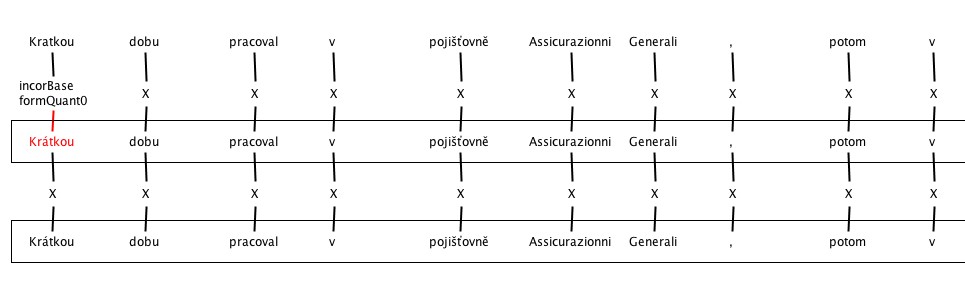
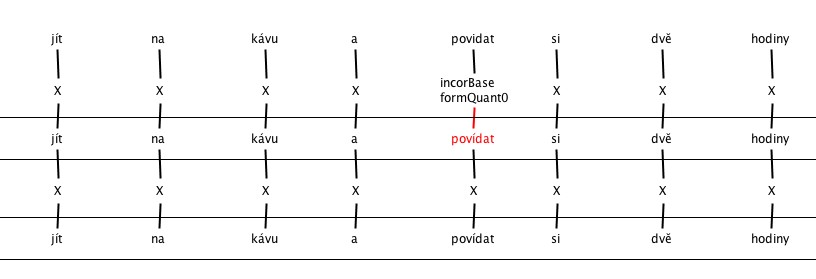
5. Incorrect inflection
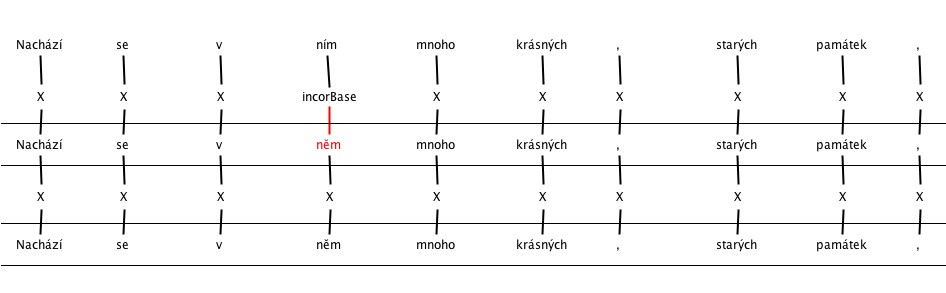
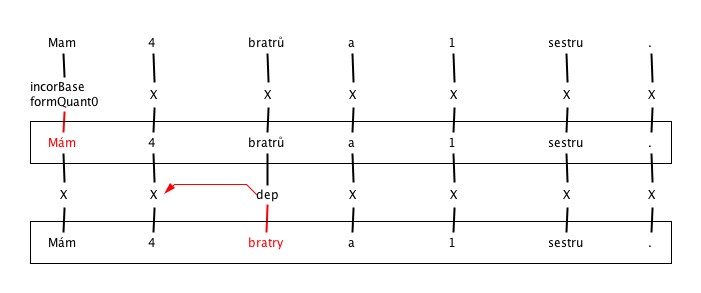
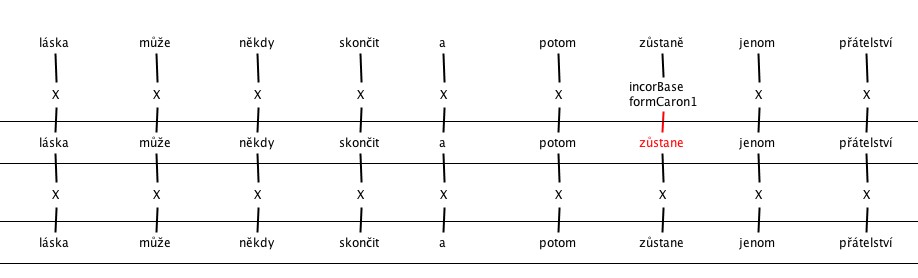
6. Various errors of Spelling
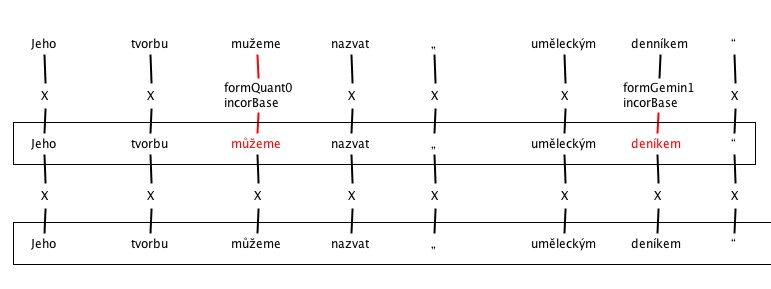
7. Grammar errors
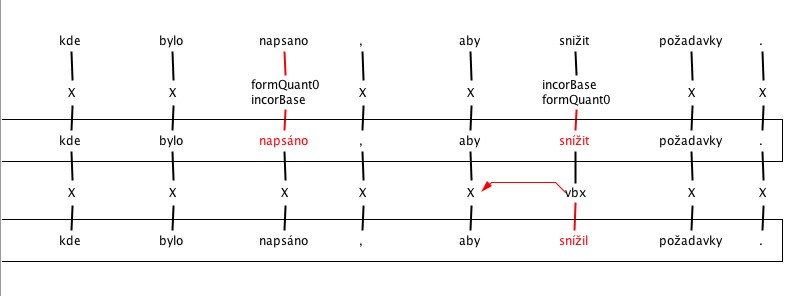
8. Errors by learners at A1